
All around the world, the hierarchical or “vertical” structure of public administration leads to challenges in addressing multidimensional or “horizontal” policy problems that cut across multiple ministries and agencies. The greater the number of vertical structures involved in the same policy area, the larger the challenge.
Such overlap in the mandate of different units, and the resulting fragmentation of the public sector, lead to well-known problems:
- Increased risk of implementing inconsistent or contradictory policy interventions.
- Diminished accountability for results, reducing the ability to learn what works (and what does not) and the incentive to deliver.
- Increased risk of internal political-bureaucratic conflict.
- Duplication of effort, with resulting inefficiencies in budget allocation and management.
- Accessing government services becomes more difficult, as there is no one-stop-shop for beneficiaries and eligibility requirements may be inconsistent across programs and services.
Despite these well-known problems, the proper measurement of public sector fragmentation still faces limitations. Most analyses are based on qualitative reviews of documentation and interviews with officials. This approach has two weaknesses. First, it is very labor-intensive, therefore analyses tend to be limited to specific policy areas. Second, it is almost impossible for any human analyst to maintain consistency when reviewing and comparing the mandates of hundreds or thousands of organizational units.
Artificial intelligence offers an answer to these methodological problems. Natural Language Processing (NLP) enables the identification of patterns in large volumes of text. Text analytics is a promising tool for the study of public administrations, which produce large amounts of documentation. By algorithmically measuring the levels of linguistic similarity in the mandates and goals of organizational units, it is possible to identify potential overlaps without problems of scale or analytical subjectivity.
It is important to note that the use of artificial intelligence in the analysis of public administration must be complemented by substantive knowledge of the field of study. Although an artificial intelligence-based methodology enables the understanding of large volumes of text that cannot be processed using traditional methods, domain expertise is still required. Therefore, this methodology does not seek to replace traditional substantive knowledge, but rather complement it, providing robust empirical evidence for experts leading public sector assessments.
The methodology proposed in this study is based on state-of-the-art NLP techniques. As a proof of concept, the study sought to identify overlapping units in the Argentine public administration, by analyzing the laws and decrees that established them. A four-stage process was used:
- Obtaining data via download of regulatory texts that define the mandates and goals of organizational units, applying “regular expressions” (character strings that are used to search for patterns) to identify relevant sections of text, and by cleaning, normalizing, and standardizing the texts.
- Vectorization of the text to quantify its properties. By extracting a text´s characteristic attributes, it is possible to represent numerically its content and identify semantic similarities between texts in a computational way.
- Clustering, with the objective of identifying how the organizational units are grouped in a vector space: more similar units are displayed close together, with less similar units located at greater distances from each other.
- Data reduction and visualization, with the objective of graphing them in a scatterplot.
Two initial applications of the methodology were employed in the study. First, a general overview of the levels of overlap and fragmentation in the Argentine public administration was compiled. Then, the methodology was applied with a specific focus on certain key policy areas.
In the first application, clusters of highly similar organizational units (ministries, deputy ministries, and undersecretariats) were identified. This enabled the detection of clusters in which more than one ministry holds responsibility, thus leading to possible overlaps (Graph 1). In the second application, levels of overlap and fragmentation were measured for two policy areas typically regarded as multidimensional: regional economic development and natural resource management. These are sectors that specialized policy literature considers to be multidimensional and therefore demand coherent participation from different government entities. The greater the fragmentation, the less likely achieving such coherence becomes.
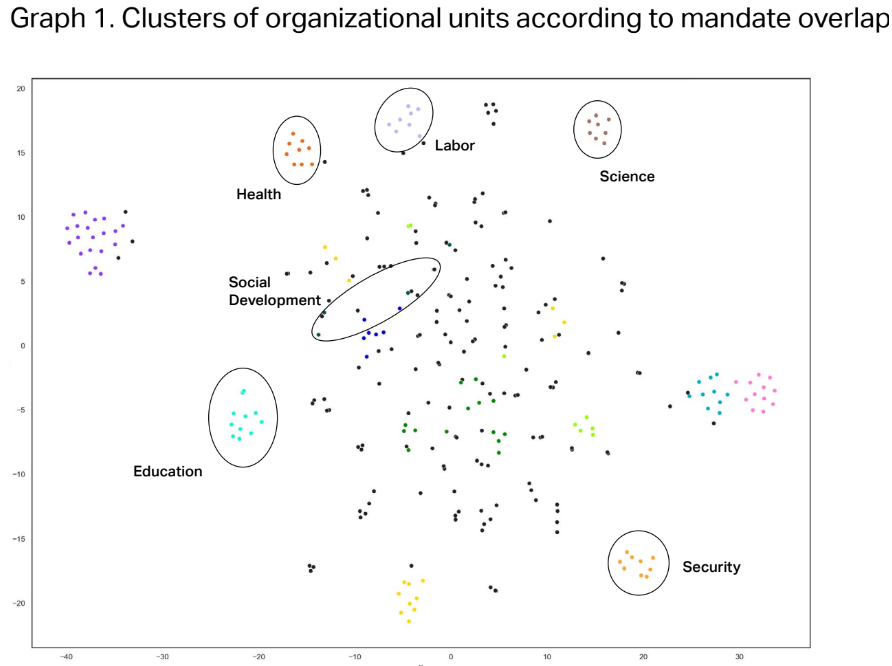

These applications of artificial intelligence generate two main contributions for practitioners. First, by rigorously measuring overlap and fragmentation in the public sector at a general level, they can be used to guide organizational redesign efforts by providing robust evidence of where the most pressing overlaps exist. Second, they can help prioritize policy areas for which central government coordination is critical, as they can compare and quantify the levels of fragmentation in each area. Instead of perceiving the state as a uniform whole, this disaggregated analysis can be a relevant input to guide coordination efforts and/or structural redesign, by directing practitioners to the policy areas where such efforts are truly needed.
