
With the emergence of GPT, generative language models (GLMs) burst into our daily lives. We use them to learn, to serve clients and even to design public policy. All the responses generated by these models (even the lack of response) reflect an opinion. Which segments of the Argentine population tend to be more present in the responses of these models? Answering this question is crucial if we want to expand the use of these tools successfully. From the lack of equal representation to the possibility of amplifying stereotypes, we analyse the challenges of these algorithmic biases.
Illustration: Micaela Nanni
What are generative large language models (LLM) and how do they work?
What are the LLM models?
They are natural language processing models, designed to interpret and answer questions in increasingly sophisticated ways. They emerged in academia, but it was the arrival of ChatGPT in November 2022 that spurred their expansion into diverse areas of society.
Since then, these models are finding applications in a variety of domains, from customer care or personalisation of recommendations to evidence-based public policy design. However, not all of their uses are virtuous. There have also been negative cases, for example in the use in governmental contexts for distorting information and generating misleading discourse to promote political or ideological agendas.
As these tools become more and more massive, responsibility for their use and understanding their ethical implications has also become an issue in itself. A fundamental question arises: to what extent do these algorithms reflect and may even amplify pre-existing biases in our society?
How do the LLM models work?
They work through prompts: prompts are given to generate specific responses or content. In other words, a prompt is a question asked of the model. The model, based on the vast amount of information it has been trained with, produces a coherent and, in many cases, surprisingly accurate answer.
This training takes place in two stages:
- Training, where the model develops essential skills, such as understanding and generating language. The process is resource-intensive and only technology giants such as Google, Meta and OpenAI have successfully implemented it. The rest benefit from models pre-trained by these companies.
- Fine-tuning, where the behaviour of each model is defined: their conversational tone, limits on their responses and friendliness, among others. This phase is less resource-intensive but demands greater human involvement to ensure that responses are aligned with specific standards.
In this fine-tuning, models may inherit biases due to human intervention that seeks to intentionally direct their behaviour. It is these biases that will subsequently cause them to answer questions based on the beliefs with which they were trained.
How do LLM models ‘get it wrong’?
They generate text by predicting the next most likely word, based on the data used during their training. They tend to express themselves with a high degree of confidence. The combination of these two characteristics can result in answers that are inaccurate or even completely fictitious, but sound authentic. Texts produced by LLMs can have the following drawbacks:
- Biases (gender, race, sexual orientation or other attributes): an incorrect or unfair representation of a population or phenomenon, given by partial or incorrect data collection or by already existing biases (present in the data collected).
- Misleading or false information: this can happen if the training data contains inaccurate information. This is especially problematic when used for consultations that require accurate information, such as medical advice.
- Hallucinations: models may generate fictitious or fabricated responses, which can be misleading or potentially harmful if users take such information as true.
- Reinforcement of pre-existing beliefs: which could lead to polarisation and lack of diversity of opinion.
Whose views reflect GPT and its competitors?
Research methodology
This research is based on a study conducted by Stanford University, which compared the responses of various generative language models (LLM), including GPT, with the opinions of US society through public opinion polls.
For this study:
- We selected a set of 78 questions and answers from the Latinobarómetro opinion poll (2020).
- We repeated the questionnaire: we asked the same survey questions to three LLM models: GPT Turbo 3.5 (OpenAI), Command-nightly (Cohere), Bard (older version of Gemini) (Google).
- We compare the responses of these 3 LLM models with those of the Argentinean population.
- We analysed commonalities and differences to identify the characteristics that each model shares with different segments of the local population.
Which segments of the population tend to be more present in the responses of LLM models?
When analysing the results, we observed that people who showed similarity in their responses to each Model (LLM) had the following characteristics:
LLM MODELS ANALYSED |
|||
|---|---|---|---|
GPT Turbo 3.5 |
Cohere |
Bard |
|
PROFILECharacteristics of the people with whom they showed the greatest similarity in their responses. |
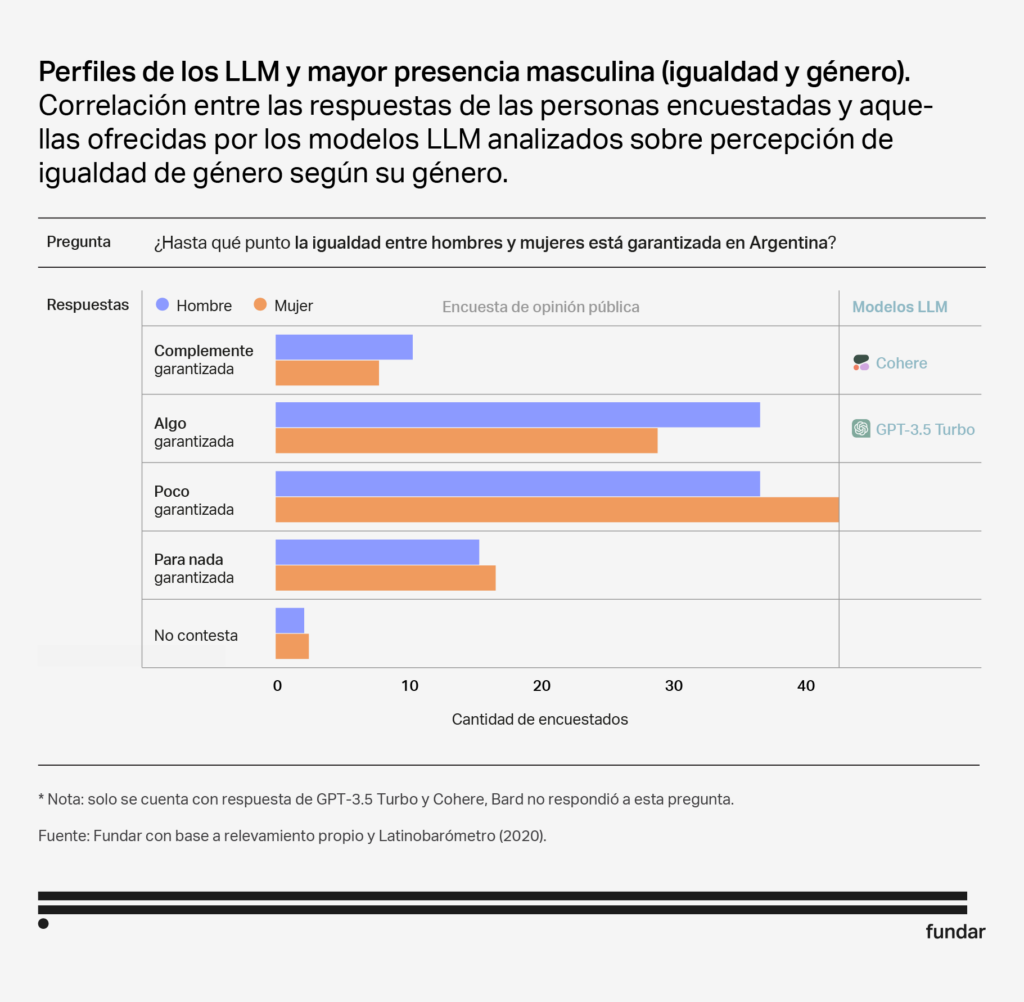
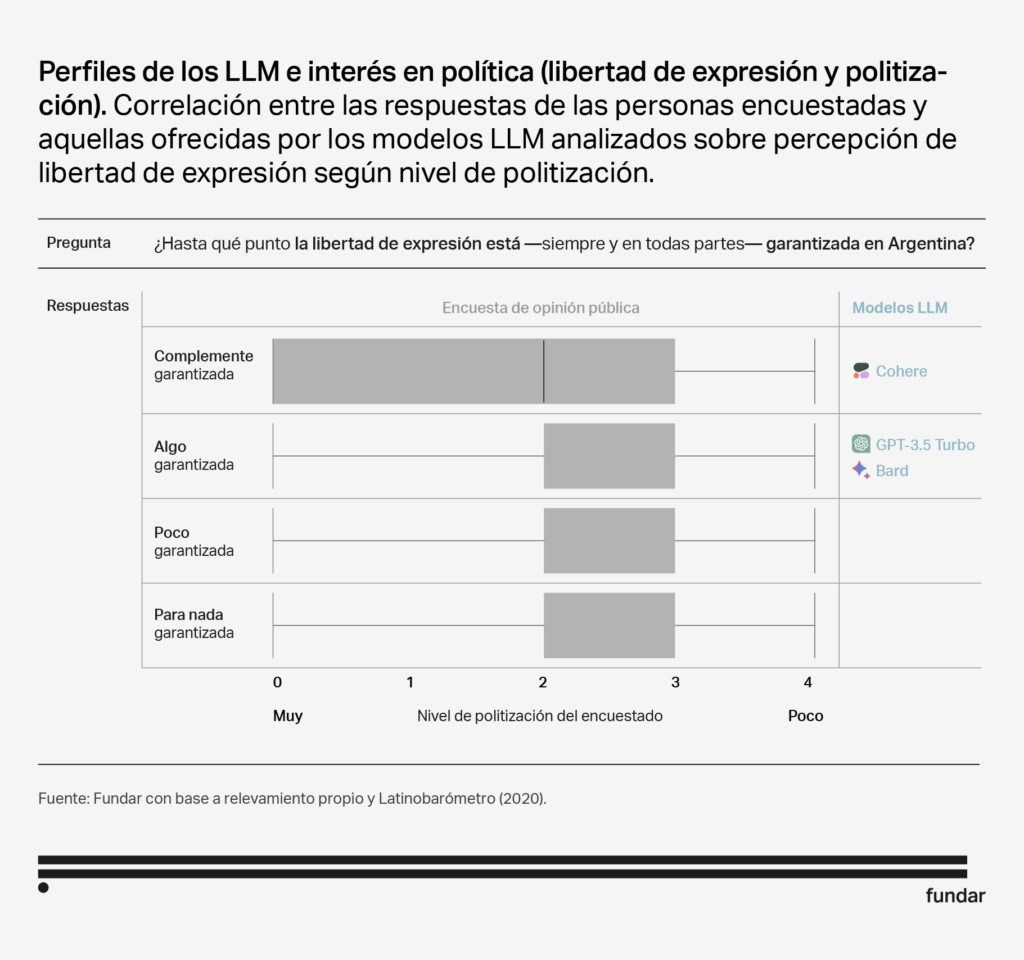
Male
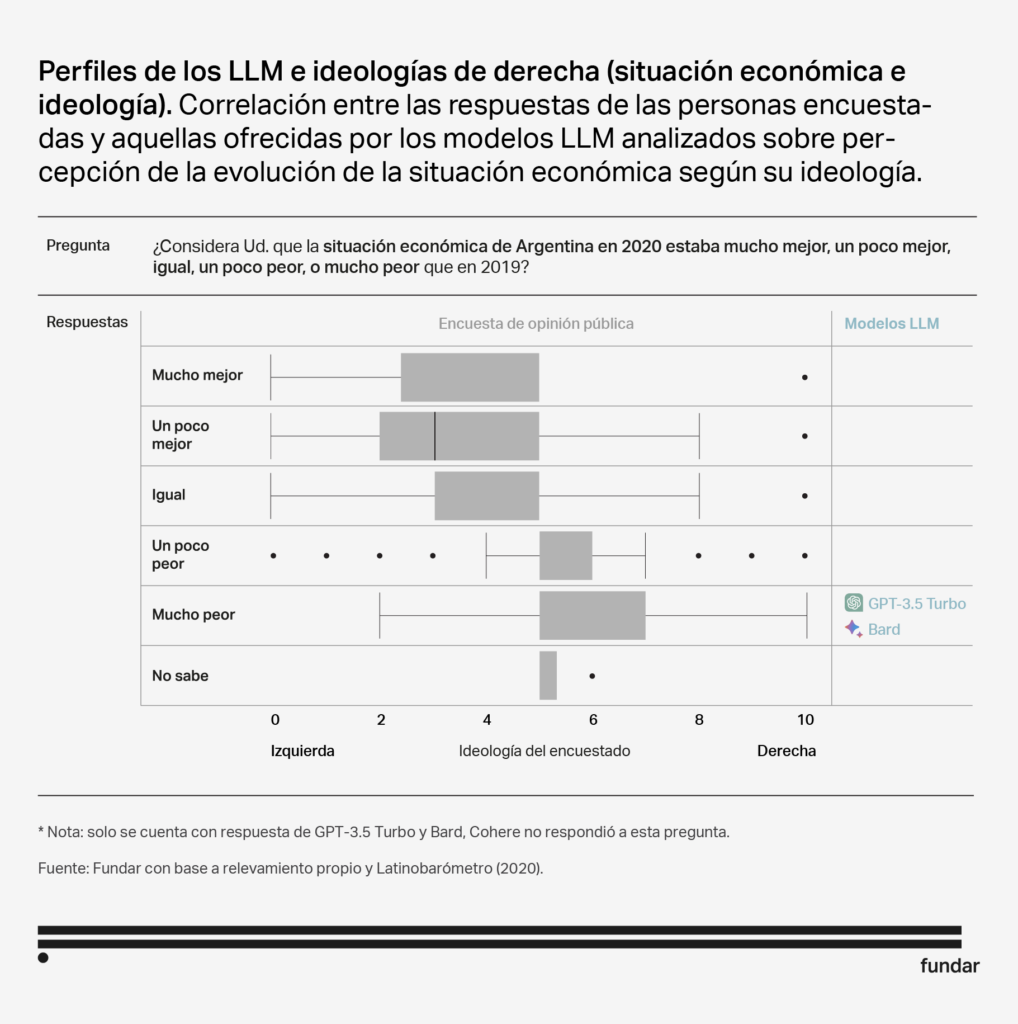
Interest in politics Adult High educational level Right-leaning ideology |
Male
Interest in politics |
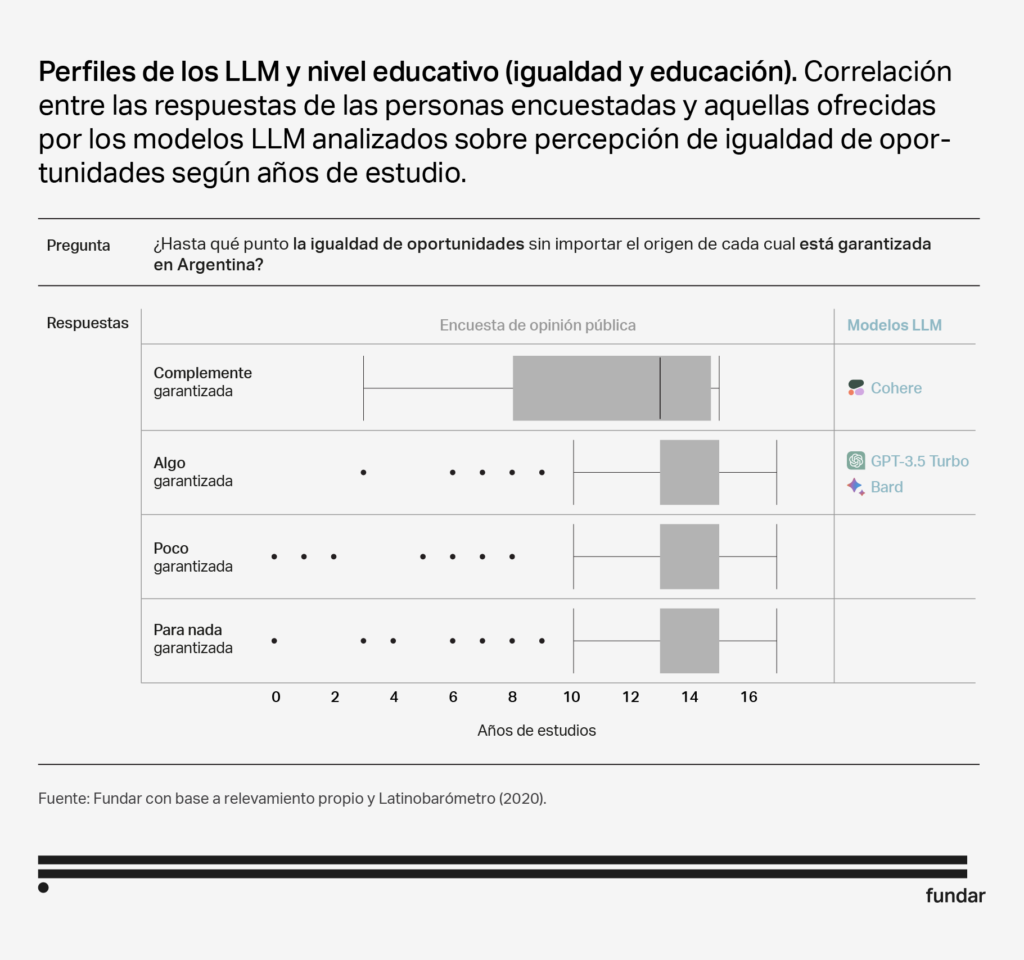
Male
Interest in politics Adult High educational level |
Profile: Male
Profile: High educational level
Profile: Interest in politics
Profile: Right-leaning ideology
LLM models characterisation
Although the responses of the 3 models are not identical, they share certain characteristics that make them similar in terms of audiences. All three models show a bias towards a more male and politicised sector. In addition, both Bard and GPT Turbo 3.5 also resemble people with higher levels of education and older age. It is worth noting that GPT Turbo 3.5 is the only one that shows a significant correlation with ideology, showing more affinity with individuals with right-wing ideological orientations.
- The affinity of these models with people interested in politics makes sense, since, during their training, they were exposed to a variety of policy-related data sources, such as social media discussions, Wikipedia definitions and essays.
- The overlap with highly educated individuals is understandable, given that these models are very knowledgeable due to their training.
- The trend towards masculinisation can be explained by the fact that, even if we do not know their exact identities, the software field tends to be dominated by men and that the majority of the authors of the founding LLM papers (13 out of 16) are men.
Profiles change according to the topics on which they are consulted
We then analyzed by topic, considering how the profiles vary according to the topics on which they are queried. Since some LLM did not answer many of these questions, we indicated “No data” when the model did not choose any of the alternatives provided.
| Topic | GPT Turbo 3.5 | Cohere | Bard |
| International Relations | No data | No data | – Adult
– Male – Right-leaning ideology – High educational level – Politicised |
| Opinion | No data | No data | – High educational level
– Do not emigrate |
| Economy | No data | No data | – Adult
– Male – Right-leaning ideology – High educational level – Desire to emigrate – Politicised |
| Democracy | No data | No data | – Left-leaning ideology
– Do not emigrate – Politicised |
| Ideology | No data | No data | – Male
– Desire to emigrate |
| Social rights | – Politicised
– Adult |
– Politicised – Adult. – Do not emigrate |
– Politicised |
Characterisation of LLM models according to topics
While there are similarities on several issues, we observe that the profiles of the models vary according to the topics asked about. For example, Bard has an affinity with a right-wing audience when asked about international relations issues, but more closely resembles a left-wing audience when asked about democracy. The same is true for his perspective on the desire to emigrate from the country. When asked about economics or ideology, they seem to have more similarities with those who wish to leave the country, but when it comes to questions related to democracy or opinion, the opposite is true.
Both GPT Turbo 3.5 and Cohere had a high number of unanswered questions: 53 out of 78 for GPT (68% unanswered) and 50 for Cohere (64%). This indicates an effort on the part of the developers to prevent these models from issuing opinions on numerous issues. In contrast, Bard refused to answer only 11 questions (only 14% unanswered), suggesting a less restrictive approach by Google.
In terms of bias, it is notable that both Bard and Cohere responded by referring to the United States when asked about “our country”. In contrast, GPT Turbo 3.5 answered that they did not know which country was being referred to. This difference highlights how developer biases may have influenced responses in possibly unintentional ways.
Good practices for the use and design of LLM models
The complete elimination of biases in general-purpose models, such as LLMs, remains a challenge without a definitive solution at present. What is currently done is to orient the behaviour of models towards what their developers consider to be the “good”. But this notion of “good” often depends on the culture and context in which it is developed. It is therefore of utmost importance to identify these biases to use this technology more responsibly and effectively, recognising its limitations and considering how it may affect various audiences and applications.
To reproduce the analysis performed in this study, you can access the repository available at the following link. This repository contains all the data and scripts necessary to replicate the procedures presented in this work. It is important to note that the code present in the repository reflects the functionality available at the time of the creation of this document. Due to possible changes in APIs or other factors, there may be variations in the results if executed at a later time.
